NLP Tranformer研修
60+ NLP Transformer模型串讲
全面剖析NLP Transformer模型以及应用
课程介绍
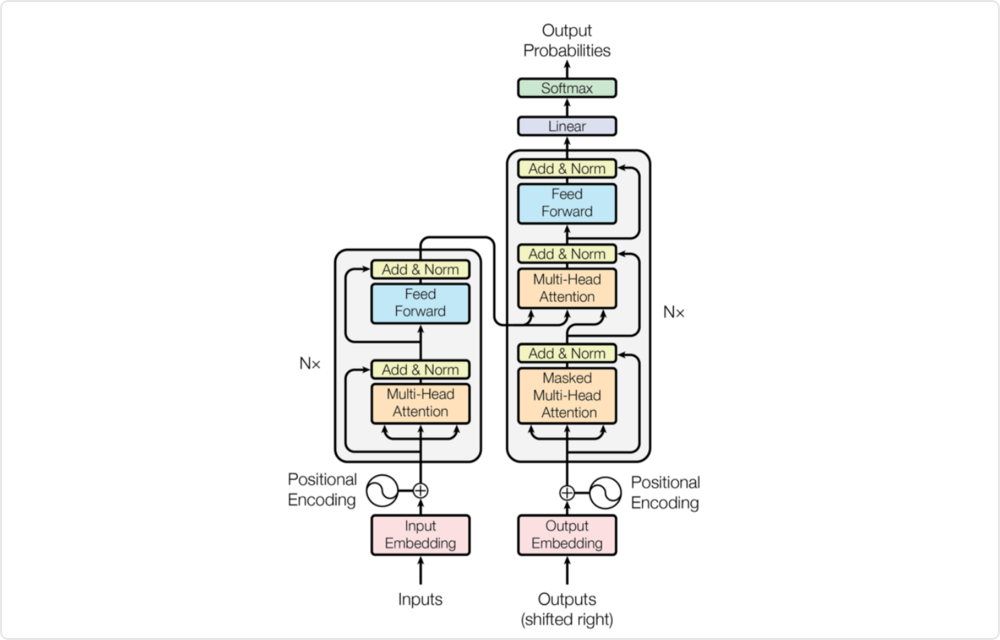
Transformer 最初是作为机器翻译的 Seq2Seq 模型提出的。后来的工作表明,基于 Transformer 的预训练模型 (PTM) 可以在各种任务上实现 SOTA。可以说Transformer的出现将 NLP 领域向前推动了一大步。其中的关键要素就是Transformer 具备:超强的序列建模能力、全局信息感知能力。目前,Transformer模型可以说是深度学习领域最强力的工具,这一模型已经成为了现代NLP技术的基石,在最近的学术研究和工业界应用中都受到了极大关注。最重要的是,Transformer模型的威力不止局限于自然语言处理领域,其在在诸如CV,量化等其他领域也有很广泛的应用。因此,Transformer基本上可以被看作是工业界的风向标, 拥有及其广阔的市场空间和职业前景。
本次课程通过知识讲解+项目实践的方式,让学员掌握各类NLP Transformer模型的原理、结构、实现方法和调参技巧,并全面了解Transformer模型在NLP中的应用。学习过程中,可以通过实现基于Transformer模型的对话系统与文本生成项目,学以致用,真正做到融会贯通。
课程亮点
全面的技术知识讲解
课程内容涵盖ELMo/GPT3/Codex/Alpha-Code/UniLM v2/BERT/RoBERTa/XLM/SpanBERT/MASS/T5/BART/Transformer-XL/XLNet/MPNet/ELECTRA/ALBERT/StructBERT等60余个模型的讲解。
项目实践,学以致用
学员使用Transformer模型,练习NLP领域应用最广泛的对话系统和文本生成任务。

专业团队严格打磨的课程内容,前沿且深入
课程内容经过前期数百小时的打磨设计,保证内容和项目节点设置合理,真正做到学有所得。

就业导向,目标明确
顺利完课后,优秀学员可获得字节、阿里、腾讯、美团等各互联网大厂,及商汤、旷视等AI独角兽公司的合作内推面试机会。
课程大纲
· ELMo
· GPT/GPT2/GPT3
· Codex/Alpha-Code
· UniLM/UniLM v2
· NLP模型中的Tokenizer(wordpiece,BPE)
· BERT/RoBERTa/XLM
· SpanBERT
· MASS
· T5
· BART
· Transformer-XL
· Relative Positional Embedding
· Permutation Language Model
· XLNet
· MPNet
· 对比学习中的常见损失函数
· 词粒度的对比:ELECTRA
· 句子粒度的对比:ALBERT,StructBERT
· 其他对比学习结构
· ERNIE/ERNIE2.0/ERNIE3.0
· KnowBERT
· K-BERT
· SentiLR
· KEPLER
· WKLM
· CoLAKE
· 多语言理解:mBERT,Unicoder,XLM-R,MultiFit
· 多语言生成:MASS,mBART,XNLG
· 处理中文的Transformer:BERT-wwm-Chinese,NEZHA,ZEN
· 适用于其他语言的Transformer:BERTje,CamemBERT,FlauBERT,RobBERT
· 对话中的Transformer模型:TransferTransfo,DialoGPT,Blender Bot,Meena,PLATO,LaMDa,GALAXY
· 文本摘要中的Transformer模型:BART,Pegasus
· 更快:Multi-query Attention, Sparse Attention,performer,fastformer
· 更大:Mixture of Expert (MoE)
· 更小:CompressingBERT,Q-BERT,ALBERT,DistillBERT,TinyBERT,MiniLM,BERT-of-Theseus
项目部分
基于Transformer的客服对话系统
项目内容描述:在本项目中,我们会带领大家实现基于Transformer模型实现自然语言理解(NLU)模块和自然语言生成(NLG)模块。客服对话系统主要实现了自动与用户进行对话的功能,并且帮助用户完成特定的任务,如订机票、酒店、餐馆等。客服对话系统是任务导向对话系统(Task-oriented Dialogue System)中最广泛的一种应用。客服对话系统中最重要的两个模块即为自然语言理解(NLU)模块和自然语言生成(NLG)模块。
项目使用的算法:TextCNN/LSTM;BERT/RoBERTa;CRF;对比学习(Contrastive Loss/Triplet Loss)
项目使用的工具:Python;Pytorch;Elasticsearch;Transformers
项目预期结果:使用基于Transformer的预训练模型实现意图识别模块:a)熟练掌握基于CNN/LSTM的文本分类/序列标注模型;b)熟练掌握基于Transformer的预训练模型的微调方法;c)掌握模型压缩的方法。使用基于Transformer的预训练模型实现检索式对话模型:a)掌握基于Elasticsearch的粗筛模块开发;b)熟练掌握基于Transformer的预训练模型的文本匹配算法
项目对应第几周的课程:1-4周
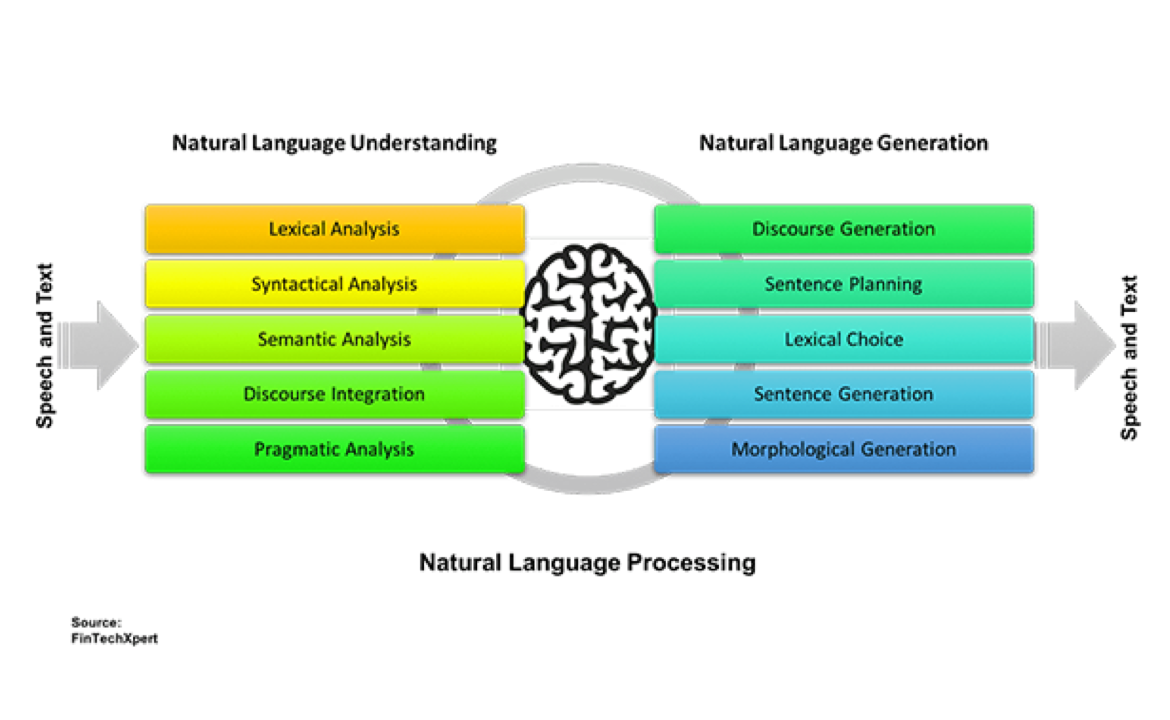
基于Transformer文本生成模型
项目内容描述:在本项目中,我们会带领大家实现基于Transformer模型的生成式NLG模型。虽然这种类型的NLG模型存在一定的不可控性,但是随着预训练模型技术的发展,我们已经可以得到非常令人振奋的生成效果。甚至在某些特定领域,基于预训练Transformer模型所构建的文本生成已经开始创造巨大的商业价值(如文本摘要,代码生成,心理咨询等)。
项目使用的算法:自回归语言模型(Auto-regressive Language Model)、Multi-input Self-Attention、Top-K/Unclear Sampling、Beam Search、Copy Mechanism
项目使用的工具:Python;Pytorch
项目预期结果:实现基于预训练Transformer的生成式NLG模型。了解文本生成模型的常用技术,包括:a)自回归语言模型中的MLE loss;b)文本生成模型中的各种解码技术;c)使用数据并行的方式利用多张GPU训练模型。有能力独立开发和优化基于预训练模型的文本生成模块。
项目对应第几周的课程:第1,2,5,6,7周
授课方式

基础知识讲解

前沿论文解读

该知识内容的实际应用

该知识的项目实战

该知识的答疑解惑

该方向的知识延伸及未来趋势讲解
课程研发及导师团队

郑老师
NLP主讲老师
清华大学计算机科学与人工智能研究部博士后;美国劳伦斯伯克利国家实验室访问学者;主要从事自然语言处理,对话领域的先行研究与商业化;先后在AAAI,NeurIPS,ACM,EMNLP等国际顶会及期刊发表高水平论文十余篇

张老师
国内top2高校cs专业毕业;主要从事自然语言处理,机器阅读理解与问答等相关研究;在BAT等公司有过算法工程师工作经验;先后在ACL、EMNLP、AAAI等会议上发表论文
Jerry Yuan
课程研发顾问
美国微软(总部)推荐系统部负责人;美国亚马逊(总部)资深工程师;美国新泽西理工大学博士;14年人工智能, 数字图像处理和推荐系统领域研究和项目经验;先后在AI相关国际会议上发表20篇以上论文
李文哲
贪心科技CEO
美国南加州大学博士;曾任独角兽金科集团首席数据科学家、美国亚马逊和高盛的高级工程师;金融行业开创知识图谱做大数据反欺诈的第一人;先后在AAAI、KDD、AISTATS、CHI等国际会议上发表过15篇以上论文
你将收获
全面掌握Transformer在NLP领域的知识,灵活应用在自己工作中
能够了解各类Transformer模型的实现方式,并熟练掌握其关键技术与方法
深入理解前沿的Transformer模型技术,拓宽工作和研究的技术视野
短期内对一个领域有全面且系统的认识,大大节省学习时间
认识一群拥有同样兴趣的人、相互交流、相互学习
适合人群

大学生

在职人士
入学标准

掌握python

具备Pytorch基础知识

具备神经网络基本知识

具备深度学习模型训练

火热招生中
¥9800