前所未有的NLP魔鬼训练营
全面剖析自然语言处理领域前沿技术:预训练、对话系统、文本生成、知识图谱、信息抽取
课程亮点

最全的贝叶斯相关内容
贝叶斯深度学习、MCMC、VAE、贝叶斯优化、主题模型等

答疑服务
即时答疑的方式,助教老师会尽快回答大家在学习中遇到的问题

深入的内容
有深度的内容、涵盖目前所能找到的最前沿的内容

专业的授课团队
在本领域有着多年工程和科研经验的导师

对科研、出国也有帮助
为以后做相关课题的科研、以及出国留学有很大帮助

提高创新能力
深入一个领域是技术创新所必须的条件
课程概要

自然语言处理在过去几年取得了飞速的发展,涌现出很多新的技术和应用场景。对于学生,还是对于职场人士,想跑在技术的前沿具有很大的挑战,毕竟涉及到的技术和内容太多。我们设计这门课程实际上就是为了帮助大家用最短的时间来跟上时代的步伐,以及让自己的知识体系更加深入。我们特意摘取了预训练、文本生成、对话系统以及知识图谱模块,也是当今应用场景最广泛的技术。在课程中,我们由浅入深的讲清楚每一个核心的细节以及前沿的技术、同时你将有机会参与到课题中,并通过课题来增加对领域的认知,让自己的能力更上一层。 课程特别适合想持续深造NLP领域的人士, 想跑在技术前沿的人士。

你将收获

全面掌握自然语言处理技术,能够灵活应用在自己的工作中

理解预训练技术、对话技术、生成技术以及知识图谱的常用技术

深入理解前沿的技术,有助于为后续的科研打下基础

完成一系列课题,有可能成为一个创业项目或者转换成你的科研论文

短期内对一个领域有全面的认识,大大节省学习时间

认识一群拥有同样兴趣的人、相互交流、相互学习
课程大纲
第一阶段:文本生成技术
大纲
第一周:Seq2Seq模型与机器翻译
第二周:文本摘要生成
第三周:Creative Writing
第四周:多模态文本生成
第五周:对抗式文本生成与NL2sql
论文列表
1、A Neural Attention Model for Abstractive Sentence Summarization
2、A Deep Reinforced Model for Abstractive Summarization
3、Incorporating Copying Mechanism in Sequence-to-Sequence Learning
4、Get To The Point: Summarization with Pointer-Generator Networks
5、Constructing literature abstracts by computer: Techniques and prospects
6、Recent automatic text summarization techniques: a survey
7、Jointly Learning to Align and Summarize for Neural Cross-Lingual Summarization
8、VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles
9、Q-learning with Language Model for Edit-based Unsupervised Summarization
10、Multi-Fact Correction in Abstractive Text Summarization
11、Incorporating Commonsense Knowledge into Abstractive Dialogue Summarization via Heterogeneous Graph Networks
12、On extractive and abstractive neural document summarization with transformer language models
13、Pre-training an Autoencoding&Autoregressive Language Model for Context-conditioned Generation
14、Re-evaluating Evaluation in Text Summarization
15、The Mathematics of Statistical Machine Translation: Parameter Estimation
16、BLEU: a Method for Automatic Evaluation of Machine Translation
17、Statistical Phrase-Based Translation
18、Hierarchical Phrase-Based Translation
19、Sequence to Sequence Learning with Neural Networks
20、Neural Machine Translation by Jointly Learning to Align and Translate
21、Adam: A Method for Stochastic Optimization
22、Neural Machine Translation of Rare Words with Subword Units
23、Attention is All You Need.
项目部分
固定项目
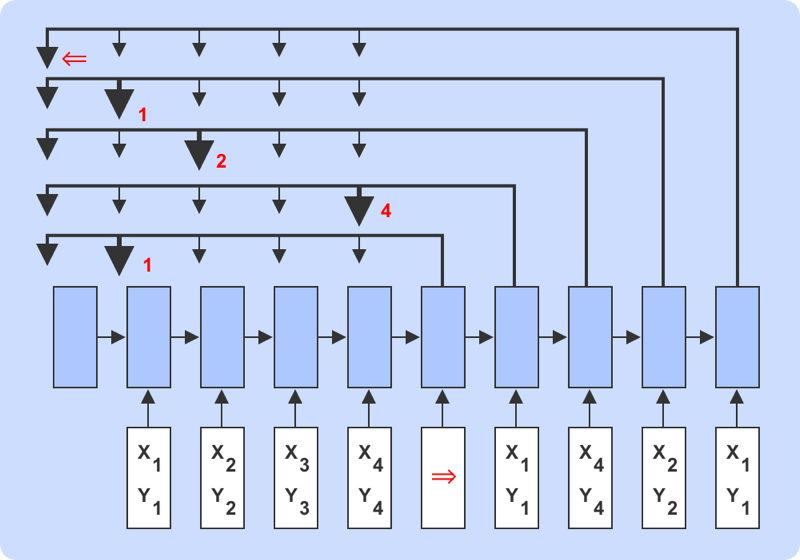
基于Pointer_Network 的文本摘要生成
概要:本项目的目的是如何基于Pointer Network 思想,进行发散来自动抽取文本中的内容以完成文本摘要生成,在本项目中,我们会引到学员使用常规的Seq2seq模型进行建模,并且使用Pointer Networks 完成Seq2seq 的改进 以及实现。通过此项目,学员会亲身体会整个摘要生成或标题文案生成的端到端模型的设计,问题的分析和训练过程。
涉及到的技术:
端到端模型
Attention
Language Generation
Transformer等
第二阶段:预训练技术
大纲
第一周:预训练模型基础
第二周:ELmo与BERT
第三周:GPT系列模型
第四周:Transformer-XL与XLNet
第五周:其他前沿的预训练模型
第六周:低计算量下模型微调和对比学习
第七周:多模态预训练和挑战
论文列表
1、Attention Is All You Need
2、Language Models are Few-Shot Learners
3、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
4、Deep contextualized word representations
5、XLNet: Generalized Autoregressive Pretraining for Language Understanding
6、BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
7、RoBERTa: A Robustly Optimized BERT Pretraining Approach
8、CogView: Mastering Text-to-Image Generation via Transformers
9、Improving Language Understanding by Generative Pre-Training
10、Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
11、ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
12、SpanBERT: Improving Pre-training by Representing and Predicting Spans
13、GPT Understands, Too
项目部分
固定项目

基于预训练模型的情感分类
概要:本项目的目的是将预训练模型应用在最常见的NLP任务:文本分类中。在本项目中,我们会引导学员在公开的benchmark数据集上实现自己的情感分类模型,并引导学员尝试不同的预训练模型和表示提取方法。
涉及到的技术:
BERT
文本分类
文本表示学习
第三阶段:对话系统技术
大纲
第一周:对话系统综述
第二周:对话系统综述
第三周:自然语言处理理解模块
第四周:对话管理和对话生成
第五周:闲聊对话系统
第六周:对话系统进阶
第七周:开源对话系统架构RASA详解
论文列表
1、Attention Is All You Need
2、Jointly Optimizing Diversity and Relevance in Neural Response Generation
3、A neural conversational model
4、A persona-based neural conversation model
5、Emotional chatting machine: Emotional conversation generation with internal and external memory
6、Commonsense Knowledge Aware Conversation Generation with Graph Attention
7、A network-based end-to-end trainable task-oriented dialogue system
8、Key-Value Retrieval Networks for Task-Oriented Dialogue
9、Hello, It’s GPT-2 - How Can I Help You? Towards the Use of Pretrained Language Models for Task-Oriented Dialogue Systems
10、Out-of-domain detection for natural language understanding in dialog systems
11、Efficient large-scale neural domain classification with personalized attention
12、ConveRT: Efficient and Accurate Conversational Representations from Transformers
项目部分
固定项目
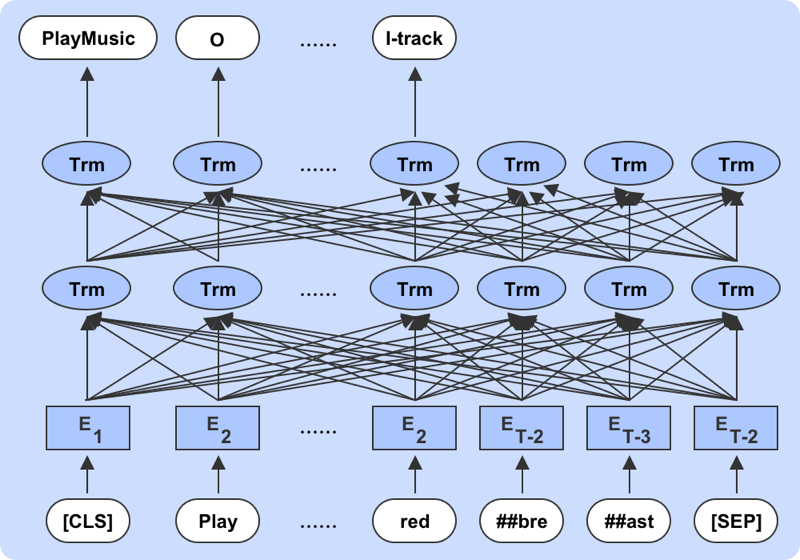
意图和槽位联合优化的自然语言理解模型
概要:本项目的目的是实现自己的自然语言理解模型。设计项目涉及到对BERT的改造,有一定的挑战性。在本项目中,我们会引导学员在公开的benchmark数据集上实现自己的意图槽位联合优化模型。
涉及到的技术:
BERT
CRF
序列标注
文本分类
多任务学习
第四阶段:信息抽取与知识图谱
大纲
第一周:知识图谱与图数据模型
第二周:知识图谱的设计
第三周:结构化预测模型
第四周:关系抽取和预测
第五周:低资源信息抽取和推断
第六周:图挖掘的热门应用
论文列表
1、Generic Statistical Relational Entity Resolution in Knowledge Graphs (Pujara et al, 2016)
2、Neural Architectures for Named Entity Recognition (Lample et al, 2016)
3、End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF (Ma & Hovy, 2016)
4、Empower Sequence Labeling with Task-Aware Neural Language Model (Liu et al, 2018)
5、Fine-grained semantic typing of emerging entities (Nakashole et al, 2013)
6、Embedding methods for fine grained entity type classification (Yogatama et al, 2015)
7、AFET: Automatic fine-grained entity typing by hierarchical partial-label embedding (Ren et al, 2016)
8、Entity linking with a knowledge base: Issues, techniques, and solutions (Shen at el, 2015)
9、Neural Relation Extraction with Selective Attention over Instances (Lin et al, 2016)
10、Heterogeneous Supervision for Relation Extraction: A Representation Learning Approach (Liu et al, 2017)
项目部分
固定项目

推荐系统设计和应用
概要:推荐系统<(Recommendation system)是根据用户的信息需求、兴趣等,将用户感兴趣的信息、产品等推荐给用户的个性化信息推荐系统。和搜索引擎相比推荐系统通过研究用户的兴趣偏好,进行个性化计算,由系统发现用户的兴趣点,从而引导用户发现自己的信息需求。推荐系统现已广泛应用于很多领域,其中最典型并具有良好的发展和应用前景的领域就是电子商务领域。同时学术界对推荐系统的研究热度一直很高,逐步形成了一门独立的学科。本项目,通过相关数据,学员需要建立对应的知识图谱,然后进行信息过滤和推断,希望能准确地将信息推荐给感兴趣的用户。
涉及到的技术:
知识图谱
相似度计算
图论
信息抽取
信息过滤
适合人群

大学生

在职人士
入学标准

理工科相关专业学生,或者IT从业者

具有良好的Python编程能力、深度学习基础

有一定的机器学习基础
或者成功完成贪心学院以下课程中的任意一门:
中级机器学习
高阶自然语言处理、或者同级别其他课程
课程团队

李文哲老师
贪心学院CEO
曾任凡普金科集团首席数据科学家、 美国亚马逊和高盛的高级工程师, 是金融行业开创知识图谱做大数据反欺诈的第一人。 美国南加州大学博士, 先后在AAAI、KDD、AISTATS、CHI等国际会议上发表过15篇以上论文

郑老师
清华大学计算机系
(计算机科学与人工智能研究部)博士后,美国劳伦斯伯克利国家实验室访问学者;美国亚利桑那大学访问学者;主要从事自然语言处理,对话领域的先行研究与商业化;先后在AAAI,NeurIPS,ACM,EMNLP等国际会议及期刊上发表过10篇以上论文

蓝振忠
贪心学院资深顾问
ALBERT模型的第一作者, 现任Google AI实验室科学家。 将于2020年6月份作为特聘研究员和博士生导师加入西湖大学,并建立”蓝振忠实验室”。 美国卡耐基梅隆大学博士。 美国NIPS举办的视频智能分析大赛连续多年TOP3 先后在NIPS, CVPR, ICCV, IJCAI等会议发表30篇以上论文,1000+ 引用次数。

史源
人工智能基金管理人
10多年人工智能领域相关研发和研究经历,负责过多项人工智能基金项目。美国南加州大学人工智能博士,卡内基梅隆大学机器人系访问学者。

Jerry Yuan
美国微软(总部)推荐系统部负责人
美国亚马逊(总部)资深工程师;美国新泽西理工博士;14年人工智能, 数字图像处理和推荐系统领域研究和项目经验;先后在AI相关国际会议上发表20篇以上论文。

杨栋老师
推荐系统,计算机视觉领域专家
香港城市大学博士, UC Merced博士后。现在主要从事于机器学习,图卷积,图嵌入的研究,从事研究多年,对机器学习有很深的理解。并且先后在ECCV, Trans on Cybernetics, Trans on NSE, INDIN等国际顶会及期刊上发表过数篇论文。
王老师
BAT高级算法工程师
毕业于QS世界综合排名top20 计算机学院,研究方向为机器阅读理解,信息检索,文本生成等,拥有新加坡国立大学,南洋理工等丰富海外访学交流经历。曾参与AAAI, ICLR 等数篇论文发表工作,拥有多项国家发明专利。现任BAT高级算法工程师,拥有亚马逊,华为,平安科技等丰富行业经历,对nlp算法及其行业落地有深入研究。
毕业证书
对于成功完成每个模块内容的学员,我们会颁发对应模块的毕业证书(注:必须要达到及格标准)

助教老师课上辅导&课下答疑
闫老师
(周一到周日)
常见问题
1、参加本课程有什么要求?
参加本课程需要一定的自然语言处理基础。
2、学完课程能达到什么水平?
能够系统性理解自然语言处理技术、有能力自主设计新的新的模型,并应用在工程中; 或者有能力从事科研相关的工作。
3、完成课题的过程是怎样的?
在每个模块的第二周开始我们会组织大家分小组定课题,在这个过程中导师团队会给修改建议,之后在课题的实施过程中,导师和助教团队也会不断地帮助大家完成课题。在最后一周,我们会组织一次线上答辩会。最后,你需要提交一份完整的技术报告。如果你完成的课题质量很高,我们导师团队乐意无偿继续提供之后的支持和帮助(比如投稿到顶会、或者对接投资人帮你孵化项目)。
4、课程中的理论和实操比例是怎样的?
课程中会有大量较为深入的技术讲解,由浅入深,理论部分会很充实。 另外,你通过完成课题的方式来完成实战部分。实战部分可以是应用型的,也可以是科研型的,就看你的兴趣。
5、课程支持哪些付费方式?
支付宝、微信、银行卡、公对公打款、paypal付款。
6、加入课程,最后怎样才能拿到证书?
对于证书我们坚持高门槛,只有达到及格线我们才会颁发证书。

火热招生中
¥29800